
Im ersten Anlauf schienen mir die Ergebnisse wenig aussagekräftig, also habe ich neue Testdaten generiert. Dieses Mal steht die dreifache Menge Datensätze zur Verfügung, die Suchkriterien bleiben die gleichen.
 Im Einzelnen:
Im Einzelnen:
- 1.000.000 Datensätze in der Haupttabelle
- 1.303.477 Datensätze in der ersten verbundenen Tabelle
- 970.129 Datensätze in der zweiten verbundenen Tabelle
- 8.332.233 Datensätze in der dritten verbundenen Tabelle
Aus NoSQL-Sicht ergeben sich daraus 1.000.000 Dokumente für deren Import ElasticSearch 1367 Sekunden (23 Minuten) und MongoDB 5767 Sekunden (96 Minuten) brauchte.
Zählperformance
Da sich beim letzten Mal eine direkte Abhängigkeit der ElasticSearch-Geschwindigkeit von der Ergebnismenge angedeutet hat, habe ich testweise die Abfrage der Datensätze ausgelassen und nur die reine Suchzeit gemessen.
ElasticSearch liefert immer die Anzahl der gefundenen Treffer mit, auch wenn diese nicht vollständig zurückgegeben werden sollen. Wird der Abruf auf genau ein Dokument beschränkt, scheint es keinen Zusammenhang mehr zwischen der benötigten Zeit und der Ergebnismenge zu geben. ElasticSearch benötigt 0,05 bis maximal 1,0 Sekunden um seinen Datenbestand zu durchsuchen, nur ein Ausreißer brauchte 3,9 Sekunden.
mySQL nahm sich für die gleichen Abfragen zwischen 5,4 und 123,3 Sekunden Zeit. Manchmal scheint hier die Ergebnismenge ausschlaggebend zu sein, aber es gibt auch Abfragen, die dieser Logik nicht folgen. Vermutlich ist eher die Komplexität der Abfrage ausschlaggebend.
MongoDB lieferte das erste Ergebnis nach 245 Sekunden, drei Abfragen liefen sogar länger als die vorgegebenen 900 Sekunden Maximallaufzeit (das letzte Mal habe ich sie bei jeweils 1346 Sekunden Laufzeit gesehen, kurz danach waren sie fertig). Um das Ergebnis im Diagramm zeigen zu können, musste ich die Zeiten durch 10 teilen, ansonsten wären auch die mySQL-Ergebnisse nicht mehr sichtbar gewesen.
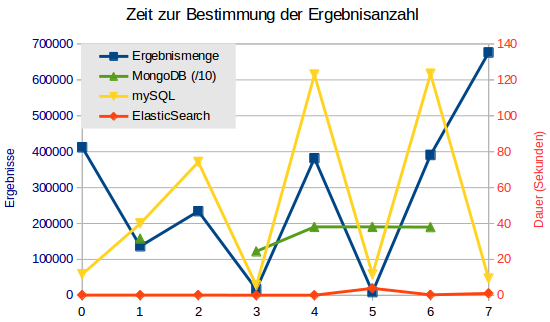 Search und Scroll
Search und Scroll
Die gleichen Abfragen mit Rückgabe der vollen Ergebnismenge führten bei ElasticSearch zu einem Serverkollaps. Der Master nahm kaum noch Anfragen an und lief sich tot. Die Such-API ist - offensichtlich - nicht für derartige Operationen gedacht, allerdings bietet ElasticSearch eine Alternative: Scroll, die optional auch auf die Sortierung der Ergebnisse verzichten kann.
Dabei wird - ähnlich einem klassischen DB-Cursor - nicht die komplette Ergebnismenge auf einmal zurückgeliefert, sondern nach Bedarf der Applikation. Perl bietet mit Search::Elasticsearch::Scroll ein passendes Modul, das nahezu das komplette Handling selbstständig übernimmt.
Mit Search brechen die ElasticSearch-Abfragen ab, wenn sie zu lange brauchen. Mit Scroll werden diese Abfragen wenigstens zu Ende verarbeitet. Allerdings bestätigt sich auch hier das Ergebnis der anderen Tests: Die Rückgabe vieler Datensätze zählt nicht zu den Stärken von ElasticSearch. Zwischen 52 und 4174 Sekunden braucht die Suchmaschine, dabei ist die Abhängigkeit von der Anzahl der Treffer eindeutig erkennbar.
Im Gegensatz zur reinen Zählung steht MongoDB besser da: Alle Abfragen brauchen ziemlich konstant zwischen 286 und 287 Sekunden, die Menge der Ergebnisse spielt keine Rolle. Vielleicht war der Test-Server bei der Zählung stärker durch andere Aufgaben belastet, anders kann ich mir die Differenzen nicht erklären.
mySQL nimmt sich mit 2 bis 40 Sekunden wesentlich weniger Zeit als die anderen Kandiaten und entscheidet den Vergleich klar für sich.
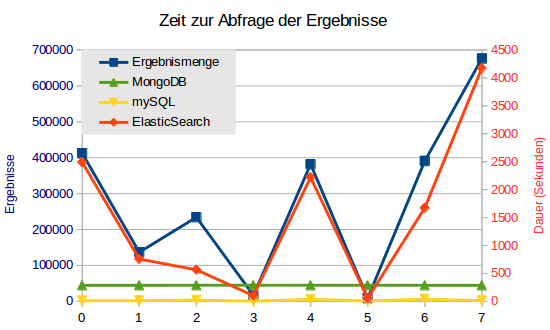 Blockgröße
Blockgröße
Nach ein paar Versuchen mit unterschiedlichen Scroll-Parametern stellte sich raus, dass ElasticSearch auch beim Scroll als Voreinstellung 10 Ergebnisse zurückliefert. Für die 676.000 Datensätze bei Abfrage Nr. 7 müssen 67.600 Suchanfragen ausgeführt werden. Bei 1.000 Ergebnissen (size => 1000) braucht Abfrage Nr. 3 nur noch 1,5 Sekunden anstatt 85 Sekunden mit der Standardeinstellung. Mit Einstellungen größer als 1.000 ergibt sich kaum eine, ab ca. 10.000 gar keine Verbesserung mehr. Grund genug, den Testlauf mit size => 10000 zu wiederholen. Bei größeren Werten wächst auch der Speicherbedarf von Server und Client immer weiter.
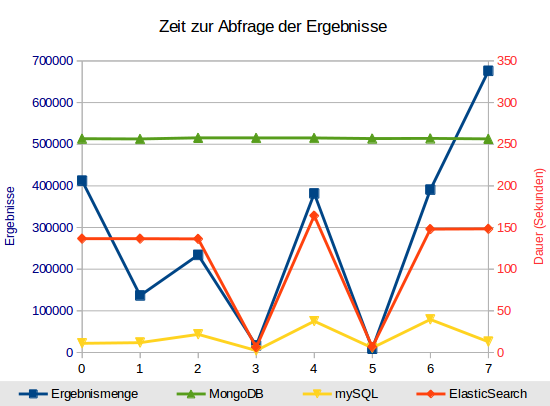 MongoDB bestätigt seine Konstanz: Rund 250 Sekunden ziemlich unabhängig von der Komplexität der Anfrage oder der Ergebnismenge. ElasticSearch fällt in zwei Fällen mit sehr wenigen Ergebnissen positiv auf, mit Scroll und 10.000er Blöcken bleibt die Suchmaschine ziemlich konstant bei rund 150 bis 160 Sekunden. mySQL bestätigt seine Zeiten.
MongoDB bestätigt seine Konstanz: Rund 250 Sekunden ziemlich unabhängig von der Komplexität der Anfrage oder der Ergebnismenge. ElasticSearch fällt in zwei Fällen mit sehr wenigen Ergebnissen positiv auf, mit Scroll und 10.000er Blöcken bleibt die Suchmaschine ziemlich konstant bei rund 150 bis 160 Sekunden. mySQL bestätigt seine Zeiten.
Fazit
ElasticSearch ist unschlagbar, wenn es um die Anzahl der Ergebnisse und die Rückgabe weniger Datensätze geht. Bei größeren Ergebnismengen ist allerdings einiges an Fine-Tuning notwendig, um eine nutzbare Performance zu erreichen. MongoDB ist am Ende zwar abgeschlagen auf dem letzten Platz, allerdings mit konstanten Zeiten, die kaum von externen Faktoren wie der Anzahl der gleichzeitigen Anfragen, die Komplexität der Filterkriterien oder der Anzahl der gefundenen Ergebnisse abhängen. mySQL gewinnt den reinen Vergleich, verhält sich allerdings im Testszenarion wesentlich performanter als unter Livebedingungen.
Anlass dieser Artikelserie war die Frage, ob mein Projekt von ElasticSearch oder MongoDB als Datenquelle für komplexe Suchanfragen profitieren könnte. Diese Frage muss ich als unbeantwortet ansehen. ElasticSearch hat mich mit den aufgetretenen Problemen und der ziemlich komplizierten Syntax überrascht. Die notwendige Einarbeitungszeit für Entwickler ist bei MongoDB definitiv kürzer. Wer bisher noch keine NoSQL-Erfahrungen hat, wird für die Umsetzung von ElasticSearch-Zugriffen nennenswert länger brauchen, als für (my)SQL-Abfragen.
Im Livebetrieb zeigen sich verschiedene Probleme mit mySQL, allen voran die Performance, aber auch der Wartungsaufwand. ElasticSearch und MongoDB könnten durch den dokumentenbasierten Ansatz auch dort eine Performancesteigerung bewirken, wo derzeit Daten mit viel Aufwand aus unterschiedlichen Tabellen gesammelt werden.
Der Wartungsaufwand wird durch den selbstverwaltenden ElasticSearch-Cluster minimiert. Im Rahmen meiner Recherchen habe ich mit unterschiedlich vielen Nodes experimentiert. Ob eine Node dabei "ausgefallen" war oder neu hinzugekommen ist - ElasticSearch hat sich selbstständig um die (Um-)verteilung der Daten gekümmert. Ein Crash des mySQL-Masters ist dagegen immer mit langen Technikereinsätzen verbunden - zumindest in unserer Umgebung.
PS: Ein paar weitere Tests mit unterschiedlich vielen gleichzeitigen Anfragen haben gezeigt, dass MongoDB auch unter höherer Last konstante, wenn auch etwa 20% langsamere Zeiten liefert. ElasticSearch verdoppelt sein Maximum bei dreifacher Anfragelast, während mySQL die zehnfache Zeit beansprucht. Hier zeigt sich vermutlich das Live-Problem: mySQL skaliert bei größeren Zugriffszahlen nicht sehr gut.




Noch keine Kommentare. Schreib was dazu