
Dieser Post wurde aus meiner alten WordPress-Installation importiert. Sollte es Darstellungsprobleme, falsche Links oder fehlende Bilder geben, bitte einfach hier einen Kommentar hinterlassen. Danke.
Nach dem sich MongoDB durchgesetzt hat und ein Objekt-Wrapper entstanden ist, geht es jetzt also an den ersten Praxiseinsatz.
Dabei zeigen sich nach und nach bisher noch unbekannte Vor- und Nachteile der Kombination Perl/Objekt-Wrapper/MongoDB und einige Klippen müssen noch umschifft werden.
Das OID-Problem
Jedes Dokument einer NoSQL-Datenbank hat eine eindeutige ID, bei MongoDB wird diese im Key _id gespeichert. Leider handelt es sich dabei beim Zugriff mit dem CPAN-Modul MongoDB nicht um einen einfachen Skalarwert (=Text), sondern um ein MongoDB::OID - Objekt. Dieses Problem hat mich einen ganzen halben Tag gekostet.Ein in einer Variablen gespeicherter ID nimmt die Objektreferenz mit, in eine HTML-Formular geschrieben und vom Browser zurückgeschickt geht diese jedoch verloren - klingt logisch. Als kleine Gemeinheit wurde keine Referenz, sondern der ID in Textdarstellung mittels bless zu einem Objekt.
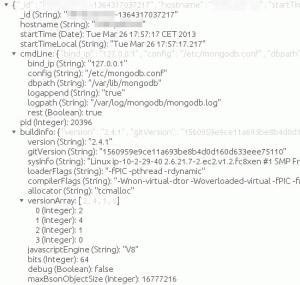
Alle Debug-Prints zeigten demzufolge 4de50e865c93120f5d000000 an und erst der Einsatz von Data::Dumper brachte das ganze Geheimnis zu Tage:
Problematisch wurde alles erst durch Moose, denn das MongoDB - Modul definiert einen abzuspeichernden Wert mittels Moose als String. Das Ergebnis war eine wenig aussagekräftige Moose - Fehlermeldung, die erst durch eine Debugger-Sitzung tief in den Innereien der verwendeten Module einen Hinweis auf des Rätsels Lösung ergab. Ohne Moose wäre das Objekt in seiner Textform abgespeichert worden und die besteht aus 4de50e865c93120f5d000000, es wäre also alles in Ordnung gewesen.
Genau so problematisch ist die Verwendung von MongoDB::OID beim Laden von Dokumenten anhand ihres IDs, denn ein ->find_one({_id => 4de50e865c93120f5d000000}) funktioniert einfach nicht, stattdessen muss jedes Mal ->find_one({ _id => MongoDB::OID->new('4de50e865c93120f5d000000') }) verwendet werden. Recht umständlich und in einer Perl-Welt ohne Typendeklarationen für Variablen eigentlich überflüssig.
Strukturierte Daten
Der große Vorteil einer dokumentenorientierten Datenbank kommt beim Speichern von Daten zum Tragen. Definiere ich normalerweise SQL-Spalten "creation_datetime" und "creation_ip", wird das bei MongoDB zu einem angenehmen$obj->{created}->{ datetime => time, ip => $remote_addr }
Endlich eine aufgeräumte Datenbank!
Das Projekt kennt zu einer Dokumententart (entspricht einer SQL-Tabelle) eine Liste von Keywords. Anstatt eine weitere Tabelle zu definieren, liegen diese jetzt als Hash-Referenzen in einem Array und können super einfach gepflegt werden.
Das Speichern von Änderungen wird dadurch allerdings nicht leichter. Ich suche immer noch nach einer "schönen" Möglichkeit, eine Änderung in einem beliebig tief verschachtelten Hash-Baum festzustellen, ohne beim Laden einen Deep-Copy und beim Speichern einen Deep-Compare auszuführen.
Deep was?
Es gibt keinen Objektbaum und kein JSON-Dokument in Perl. Stattdessen kann jeder Wert eines Hashes oder Arrays eine Referenz sein - und dadurch sieht ein einfaches Hash im täglichen (Programmierer-)Leben wie in Baum aus.Bei einem normalen %hash2 = %hash1 werden einfach nur die Referenzen kopiert, aber $hash1{key}->{foo} zeigt danach auf die gleiche Speicherstelle wie $hash2{key}->{foo}.
Bei einem Deep-Copy wird jede einzelne Referenz ebenfalls kopiert, so dass alle Daten tatsächlich ein zweites Mal im RAM liegen und bei einem Deep-Compare auch bis in den letzten kleinen Zweig des Baumes auf Unterschiede kontrolliert werden.
Wenn mehr Interesse an diesem Thema vorhanden ist, schreibt bitte einfach einen Kommentar und ich werde in einem anderen Beitrag intensiver auf das Thema eingehen.





3 Kommentare. Schreib was dazu-
![]()
Sid Burn
1.06.2011 12:23
Antworten
-
![]()
Sid Burn
1.06.2011 12:41
Antworten
-
![]()
Sebastian
3.06.2011 11:05
Antworten
Also das mit MongoDB::OID wird eigentlich alles bereits im Tutorial erklärt: http://search.cpan.org/perldoc?MongoDB::Tutorial
Ansonsten wenn du Moose für deine Klassen nutzt kannst du dank Coercion auch simpel ein String übergeben und Die klasse macht die umwandlung nach MongoDB::OID. Natürlich kannst du das auch jederzeit selber machen wenn du deine eigene Klasse baust. Das ganze würde mit Moose so aussehen:
http://pastebin.com/CMxFjGXP
Und für deine Änderung, schreibst du keine Klasse drum herum die eben deine änderung händelt? Für Felder auf der normalen Ebene würde ich einfach alle Felder direkt updaten. Bei Arrays/Hashes ist das ja wieder ein Punkt wo man in der Regel wieder eine neue Klasse daraus machen würde und diese kann dann seine änderungen ja wieder selber pflegen. Letzteres habe ich aber auch noch keinen konkreten Plan. Ich hoffe das ich über das lange Wochenende etwas Zeit zum Programmieren finde, dann werde ich mal schauen wie ich es im Detail löse.
Achso, überflüssig ist das nicht. Auch Intern stellt MongoDB das _id Attribut als Objekt von ObjectId() dar und eben nicht als String. Wenn du einfach mal ein db.collection.find() machst dann siehst du das auch.
Da du jederzeit an diversen stellen eine ObjectId() einfügen kannst, dass ist ja nunmal nicht auf _id begrenzt musst du in Perl genauso eben solch ein Objekt darstellen können. Und du musst sagen können ob du nunmal ein ObjectId() haben willst oder ein String.
Es ist das gleiche wie bei einem Datum wofür MongoDB ebenfalls eine spezielle repräsentation hat, möchtest du diese nutzen musst du ein DateTime Objekt übergeben. Ein String zu Speichern das ein Datum repräsentiert geht natürlich auch, ist aber nicht das gleiche als wenn MongoDB direkt über den Datum Typ bescheid weis. In MongoDB::DataTypes werden noch mehr spezielle Typen aufgelistet.
Ich bin wohl einfach etwas zu sehr vom typenlosen Perl verwöhnt :-)
Man kann jetzt drüber streiten, ob eine ObjectID wirklich etwas anders als ein String sein muss, aber ich sehe ein, dass es bei einem Low-Level - Modul wie MongoDB besser ist, die Datenbankseite möglichst unverfälscht abzubilden. Die Beschreibung von MongoDB::OID im Tutorial finde ich etwas "kurz" und wenig hilfreich.
Aber saubersten wäre es mit Sicherheit, den Hash-Tree komplett als Objektbaum abzubilden, bisher habe ich mich aus Faulheit davor gedrückt, allerdings kam mir gestern eine (hoffentlich) coole Idee das Ganze zu vereinfachen. Bevor ich die publiziere, muss sie sich erstmal als realisierbar erweisen :-)
Wie immer: Danke für Dein Feedback!